Ring buffers in io_uring with dynamic allocation
io_uring is a Linux I/O interface introduced in version 5.1, designed to provide more scalable asynchronous I/O operations compared to interfaces like epoll or select. One of the caveats when using io_uring is allocation and management of resources that are dynamic/weak in the io_uring data structures, i.e. submission queue entries (SQEs) and completion queue entries (CQEs).
It may not be apparent what occurs during the lifecycle of
io_uring-related allocations especially when it does not entail resource auto-management, which is why I decided to write on this.
Initializing io_uring with a memory map #
Before using io_uring, we must allocate memory for both the submission and completion queues. This is handled internally by the kernel, but userspace still needs to understand the memory layout and control structures.
When setting up io_uring, the io_uring_setup syscall is invoked which allocates kernel structures for the ring buffers (submission and completion queues) and memory-maps them into userspace.
#include <liburing.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
int setup_io_uring(struct io_uring *ring, unsigned entries) {
struct io_uring_params params;
memset(¶ms, 0, sizeof(params));
// `io_uring_queue_init_params` internally calls `io_uring_setup`, which requests the kernel to
// allocate memory for `io_uring` data structures and map them into the application's address space.
// The number of entries requested is a power-of-two, and the kernel will round it up if needed.
int ret = io_uring_queue_init_params(entries, ring, ¶ms);
if (ret < 0) {
perror("io_uring_queue_init");
return -1;
}
return 0;
}
int main() {
struct io_uring ring;
if (setup_io_uring(&ring, 256) != 0) {
return 1;
}
io_uring_queue_exit(&ring);
return 0;
}Submission queue allocation #
The submission queue (SQ) consists of two main components: the submission queue itself and the array of submission queue entries (SQEs). The SQ is used to notify the kernel about I/O requests, while SQEs hold the actual I/O operations data.
- Submission Queue Control Block (SQE): Each I/O operation submitted to the kernel is represented by an SQE. The kernel maps a region of memory for these entries into the user-space process.
The following structure represents an SQE:
struct io_uring_sqe {
__u8 opcode;
__u8 flags;
__u16 ioprio;
__s32 fd;
__u64 off;
__u64 addr;
__u32 len;
union {
__kernel_rwf_t rw_flags;
__u32 fsync_flags;
__u16 poll_events;
__u32 sync_range_flags;
__u32 msg_flags;
__u32 timeout_flags;
__u32 accept_flags;
__u32 cancel_flags;
__u32 open_flags;
__u32 statx_flags;
__u32 fadvise_advice;
__u32 splice_flags;
};
__u64 user_data;
union {
// this may just be __u16 buf_index
struct {
__u16 buf_index;
__u16 personality;
};
__u64 __pad2[3];
};
};The application submits I/O requests by filling out SQEs and placing them into the submission queue. The kernel processes these entries in batches to minimize the overhead of syscalls.
- Memory-Mapping the Submission Queue: When
io_uringis set up, both the submission queue and the SQEs are memory-mapped to userspace. This avoids unnecessary memory copies between user and kernel space.
In userspace, after mapping the memory, SQEs can be directly accessed and populated with I/O operation metadata.
To submit a read operation to a file descriptor, io_uring_get_sqe returns an SQE that is part of the pre-allocated memory block, avoiding the need for dynamic memory allocation for each individual SQE:
struct io_uring_sqe *sqe = io_uring_get_sqe(&ring);
if (!sqe) {
perror("io_uring_get_sqe");
return 1;
}
io_uring_prep_read(sqe, fd, buf, BUF_SIZE, 0);Completion queue allocation #
Once the I/O request is completed, the results are posted to the completion queue (CQ). Similar to the submission queue, the completion queue is also memory-mapped from the kernel into userspace. The completion queue contains completion queue entries (CQEs), which provide metadata about the result of the I/O operation.
Each CQE has the following structure:
struct io_uring_cqe {
__u64 user_data; // tracks which I/O operation this completion corresponds to
__s32 res; // number of bytes read or written, or an error code
__u32 flags; // optional flags related to the completion
};Accessing the completion queue is similar to the submission queue, where we fetch a CQE from the ring:
struct io_uring_cqe *cqe;
if (io_uring_wait_cqe(&ring, &cqe) < 0) {
perror("io_uring_wait_cqe");
return 1;
}Performance regressions #
One key feature of io_uring is its evasion of unnecessary syscalls for each I/O operation. By memory-mapping both the submission and completion queues, the kernel and userspace share these buffers, which enables batch processing and reduced call overhead (for latency/throughput). Additionally, because the buffers are pinned in memory, they cannot be swapped out to disk, ensuring that the kernel always has direct access to the data without requiring page faults or additional memory management overhead.
Memory pinning #
Memory pinning is managed automatically by the kernel when setting up io_uring. Excessive use of pinned memory can lead to system performance degradation, since it reduces the amount of memory available for other processes, which is why it is often intuitive to avoid requesting an excessively large number of queue entries.
What I think could work in the case where it is necessary to repeatedly request queue entries, is either introducing a custom I/O batching procedure + LRU cache for elements or using paged allocation individually on the elements in the io_uring structures, but this is unrelated.
SQ/CQ ring buffer layout #
Internally, the submission and completion queues are managed using ring buffers. The head and tail indices are shared between userspace and the kernel to keep track of the state of the queues.
sq_ring- points to the start of the submission queue ring buffer.cq_ring- points to the start of the completion queue ring buffer.sqes- points to the array of SQEs.

The user modifies the tail to add new entries, while the kernel updates the head to indicate processed entries. Similarly, for the completion queue, the kernel updates the tail, and the user reads the entries and modifies the head.
I/O buffer allocation #
In addition to the queues themselves, you must also allocate buffers for performing I/O. This can be done using malloc, mmap, or any other mechanism that fits the intended use case.
Once the buffer is allocated, its address can be passed to the kernel through the SQE for reading or writing operations. This case works for dynamically allocating objects of known size at runtime, with the obvious risks of malloc.
Latency in buffer allocation scaling with I/O #
I/O is required to scale with the initial buffer's size. We will try this with liburing where we take the memory usage after each step.
import liburing
import os
import psutil
import matplotlib.pyplot as plt
def get_memory_usage():
process = psutil.Process(os.getpid())
return process.memory_info().rss / 1024 / 1024 # aggregate memory in MBThe goal is to evade any spill over of I/O-bound memory, so the main metric here will be memory usage. Initially, we start with a 4 kB buffer size and a single line of text. I tried this multiple times to get the metrics for a warm start.
# measure memory before io_uring setup
mem_before = get_memory_usage()
# set up io_uring
ring = liburing.io_uring()
liburing.io_uring_queue_init(1 << (1 << 3), ring)
# measure memory after io_uring setup
mem_after_setup = get_memory_usage()
# open file O_RDONLY for fd
fd = os.open('example-1.txt', os.O_RDONLY)
# allocate a 4 kB buffer
BUF_SIZE = 4096
buf = bytearray(BUF_SIZE)
# measure memory after buffer allocation
mem_after_buf_alloc = get_memory_usage()Our example-1.txt is a single-line lorem ipsum. The results for this are trivial, usage between setup and allocation is greatly diminished (which contrasts with the overhead of using io_uring):
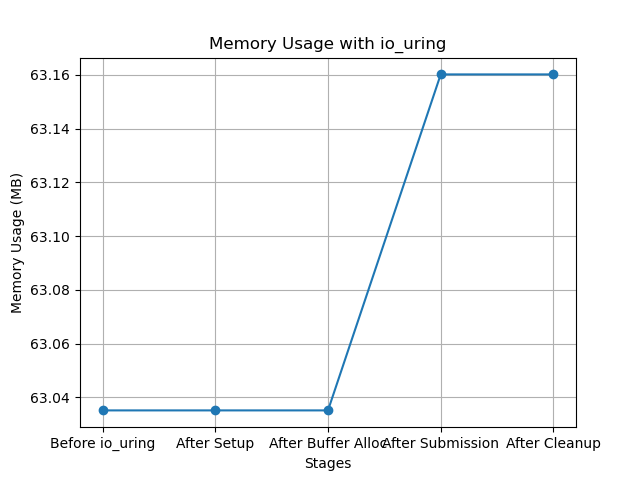
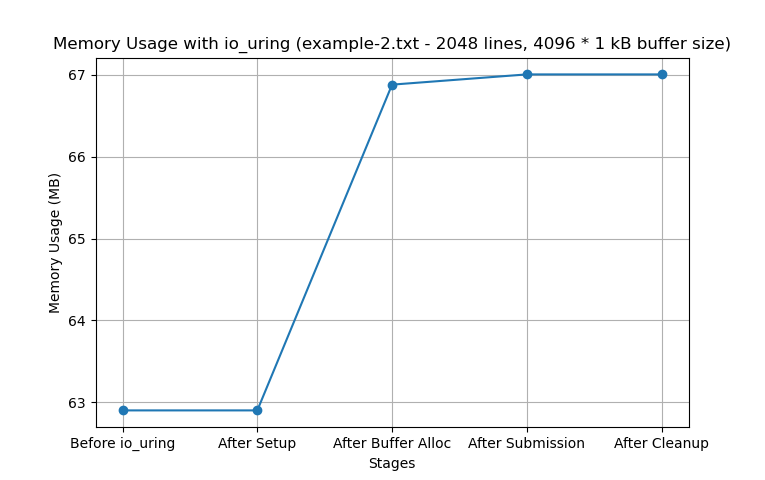
In the next test, we collect memory usage after a warm run with a 4 MB buffer size and 2048 lines (example-2.txt).
fd = os.open('example-2.txt', os.O_RDONLY)
BUF_SIZE = 4096 * 1024
buf = bytearray(BUF_SIZE)After submitting the I/O request, memory usage stabilizes. Once the io_uring instance is cleaned up and resources are freed, memory usage decreases back (close) to its initial state.
# measure memory after buffer allocation
mem_after_buf_alloc = get_memory_usage()
# prepare the SQE for a read operation
sqe = liburing.io_uring_get_sqe(ring)
liburing.io_uring_prep_read(sqe, fd, buf, BUF_SIZE, 0)
# submit the request
liburing.io_uring_submit(ring)
# wait for the completion event
cqe_ptr = liburing.io_uring_cqe()
liburing.io_uring_wait_cqe(ring, cqe_ptr)
# measure memory after io_uring submission
mem_after_submission = get_memory_usage()
# clean up
os.close(fd)
liburing.io_uring_queue_exit(ring)
# measure memory after io_uring cleanup
mem_after_cleanup = get_memory_usage()io_uring_get_sqe(ring) fetches an SQE, which is an entry where the details of the I/O operation (such as the file descriptor, buffer, and operation type) are populated. io_uring_prep_read(sqe, fd, buf, BUF_SIZE, 0) sets up a read operation in the SQE, specifying the file descriptor, buffer, buffer size, and offset (0 for start). The ring's SQE is submitted to the submission queue, and the kernel starts processing the I/O request asynchronously.
io_uring_wait_cqe(ring, cqe_ptr) blocks the program until the kernel has completed the I/O request and a completion queue entry (CQE) is available. Once a CQE is available, cqe.res contains the result of the operation (number of bytes read, error code, etc).